
1. Executive Summary
This report analyses how minor variations in prompt phrasing affect brand visibility and source selection in AI-generated answers, using a set of seven semantically similar prompts about CRM software for small and medium-sized businesses in 2026. The seven prompts differ only in their choice of qualifying adjective (“top”, “best”, “leading”), product noun (“tools”, “platforms”, “solutions”, “software”), and the abbreviation for business size (“medium-sized” vs. “mid-sized”).
Key finding: AI models maintain a near-rigid brand ranking hierarchy regardless of phrasing, but the absolute visibility percentages — particularly for mid-tier brands — are meaningfully affected by word choice. Source selection is considerably more volatile: only 3 of 22 unique domains appear consistently in the top ten across all seven prompts.
The practical implication is clear: a single prompt is insufficient to accurately measure a brand’s AI visibility. A robust tracking methodology requires multiple prompt variants to capture the full range of exposure and source behaviour.
2. Research Setup & Methodology
Seven prompts were submitted to an AI model, each targeting the same intent: identifying the best CRM tools for SMBs in 2026. For each prompt, two data outputs were captured:
- Leaderboard: A ranked list of ten CRM brands with an associated visibility score (%), indicating how prominently the brand appears in AI-generated answers for that prompt.
- Sources: The top ten source URLs the AI cited or referenced when formulating its answer, each with a “# used” count and a citation coverage percentage.
The seven prompts tested were:
| # | Prompt | Key variable |
| P1 | What are the top CRM tools for small and medium-sized businesses in 2026? | “top” + “tools” |
| P2 | What are the best CRM tools for small and medium-sized businesses in 2026? | “best” + “tools” |
| P3 | What are the leading CRM tools for small and medium-sized businesses in 2026? | “leading” + “tools” |
| P4 | What are the best CRM platforms for small and medium-sized businesses in 2026? | “best” + “platforms” |
| P5 | What are the best CRM solutions for small and medium-sized businesses in 2026? | “best” + “solutions” |
| P6 | What are the best CRM software tools for small and medium-sized businesses in 2026? | “best” + “software tools” |
| P7 | What are the best CRM tools for small and mid-sized businesses in 2026? | “mid-sized” vs. “medium-sized” |
Each prompt was executed 1,176 times to obtain a statistically meaningful sample.
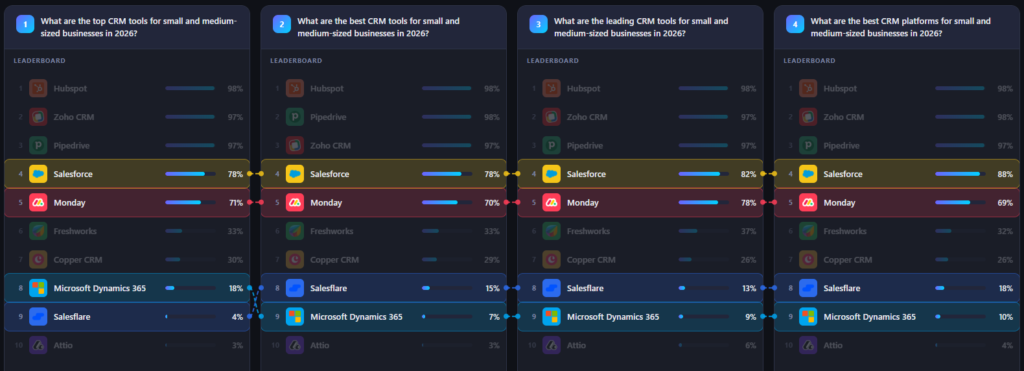
3. Impact of Wording on Brand Visibility Scores
Research question: How much does slight wording variation impact brand visibility (%) in AI-generated answers?
Visibility scores vary considerably by brand tier. The table below shows the minimum, maximum, and range in visibility percentage across all seven prompts for each brand, ordered by position.
| Brand | Rank | Min % | Max % | Range | Std. Dev. |
| Hubspot | 1 | 98% | 98% | 0% | 0.0 |
| Zoho CRM | 2–3 | 96% | 98% | 2% | 0.7 |
| Pipedrive | 2–3 | 96% | 98% | 2% | 0.7 |
| Salesforce | 4 | 78% | 91% | 13% | 5.4 |
| Monday | 5 | 59% | 78% | 19% | 6.5 |
| Freshworks | 6 | 32% | 37% | 5% | 1.7 |
| Copper CRM | 7 | 20% | 30% | 10% | 3.2 |
| Microsoft Dynamics 365 | 8–9 | 7% | 18% | 11% | 3.9 |
| Salesflare | 8–9 | 4% | 18% | 14% | 5.0 |
| Attio | 10 | 2% | 6% | 4% | 1.4 |
Three distinct tiers of sensitivity emerge:
- Immune tier (rank 1–3): Hubspot, Zoho CRM, and Pipedrive are virtually unaffected by phrasing. Their visibility scores cluster within a 2-percentage-point band, suggesting these brands are so strongly associated with the category that no tested variation can meaningfully shift their representation.
- Sensitive tier (rank 4–5): Salesforce and Monday exhibit the highest absolute variance. Monday’s 19-point range (59–78%) and Salesforce’s 13-point range (78–91%) demonstrate that mid-tier brand representation is genuinely responsive to prompt wording. For these brands, the choice of adjective or noun in a query can shift their AI share of voice by roughly one-fifth of their total score.
- Volatile lower tier (rank 6–9): Salesflare (14-point range) and Microsoft Dynamics 365 (11-point range) show disproportionate sensitivity relative to their already-low absolute scores. A swing from 4% to 18% for Salesflare represents a 4.5× difference, significant from a competitive intelligence standpoint.
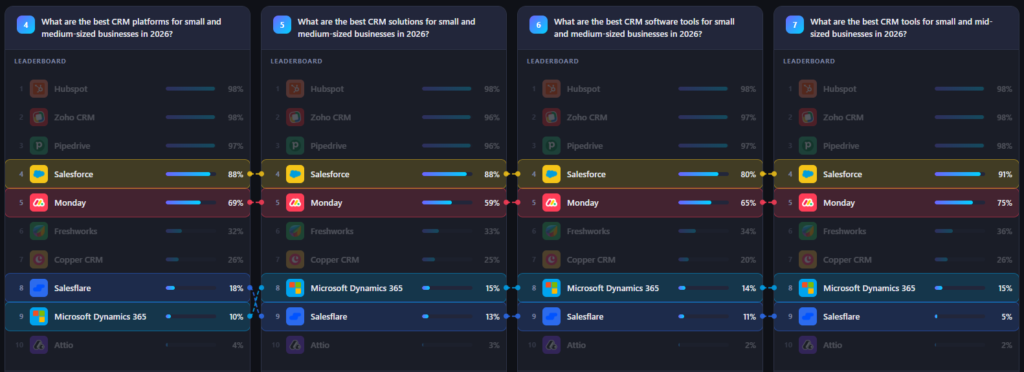
4. Which Phrasing Maximises Share of Voice Per Brand?
Research question: Which phrasing leads to the highest share of voice for a given brand?
| Brand | Highest Visibility | Prompt | Key phrasing |
| Hubspot | 98% (all) | P1–P7 | No variation — always maximum |
| Zoho CRM | 98% | P4, P7 | “platforms” / “mid-sized” |
| Pipedrive | 98% | P2, P7 | “best tools” / “mid-sized” |
| Salesforce | 91% | P7 | “mid-sized” |
| Monday | 78% | P3 | “leading” |
| Freshworks | 37% | P3 | “leading” |
| Copper CRM | 30% | P1 | “top” |
| Microsoft Dynamics 365 | 18% | P1 | “top” |
| Salesflare | 18% | P4 | “platforms” |
| Attio | 6% | P3 | “leading” |
Two words stand out as particularly powerful activators for mid-tier brands:
- “Leading” (P3) consistently elevates visibility across ranks 5–10. It appears to activate training data that includes more editorial and analyst-style content, where a broader set of brands receives substantive coverage.
- “Mid-sized” (P7) instead of “medium-sized” triggers a different lexical cluster in training data, yielding the highest Salesforce score (91%) and elevated Zoho and Pipedrive scores — suggesting these terms map to different content corpora despite being semantically identical.
5. Consistency of Visibility Rankings Across Semantically Similar Prompts
Research question: How consistent are brand rankings across semantically similar prompts?
The visibility ranking hierarchy is strikingly stable. Across all 70 data points (10 brands × 7 prompts), only two position swaps were observed: Zoho CRM and Pipedrive occasionally exchange positions #2 and #3, and Salesflare and Microsoft Dynamics 365 trade places between positions #8 and #9. Every other brand holds its exact visibility ranking in every single prompt.
8 out of 10 brands are positionally locked. No tested prompt variation was able to change a brand’s rank by more than one position, and only 4 brands ever experienced even that degree of movement.
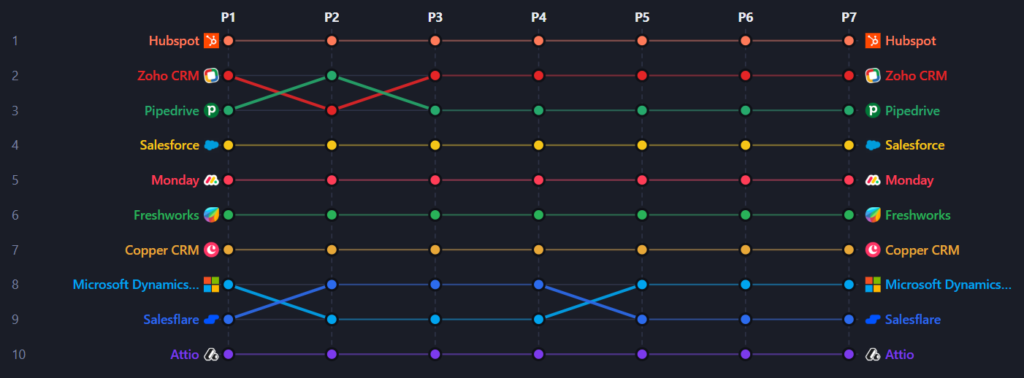
This stability suggests that the AI has a deeply ingrained, training-data-derived opinion about which CRM brands are most relevant for this query type. The ranking appears to be driven by the volume and authority of training content about each brand in the SMB CRM context, a signal that is not easily perturbed by synonym substitution.
7. Are Top Positions (1–3) More Stable Than Lower Positions?
Research question: Are top positions (1–3) more stable than lower positions?
Yes, but the pattern is more nuanced than a simple top-vs-bottom split. Positions 1 through 7 are all positionally stable when you look at their visibility %. The only rank instability in the entire dataset occurs at positions 8–9.
This creates a counter-intuitive finding: the least stable zone is the lower-mid tier (rank 8–9), not the bottom. This is likely because Salesflare and Microsoft Dynamics 365 occupy a contested margin where neither brand has a clear dominance signal in training data for this query type. A minor shift in prompt phrasing is enough to tip the AI’s implicit weighting in favour of one over the other.
Implication for competitive tracking: If your brand sits in the rank 7–10 range for a given category, you are in the most volatile monitoring zone. Small prompt variations can place you above or below a direct competitor. Tracking multiple prompt formulations is especially critical at this tier.
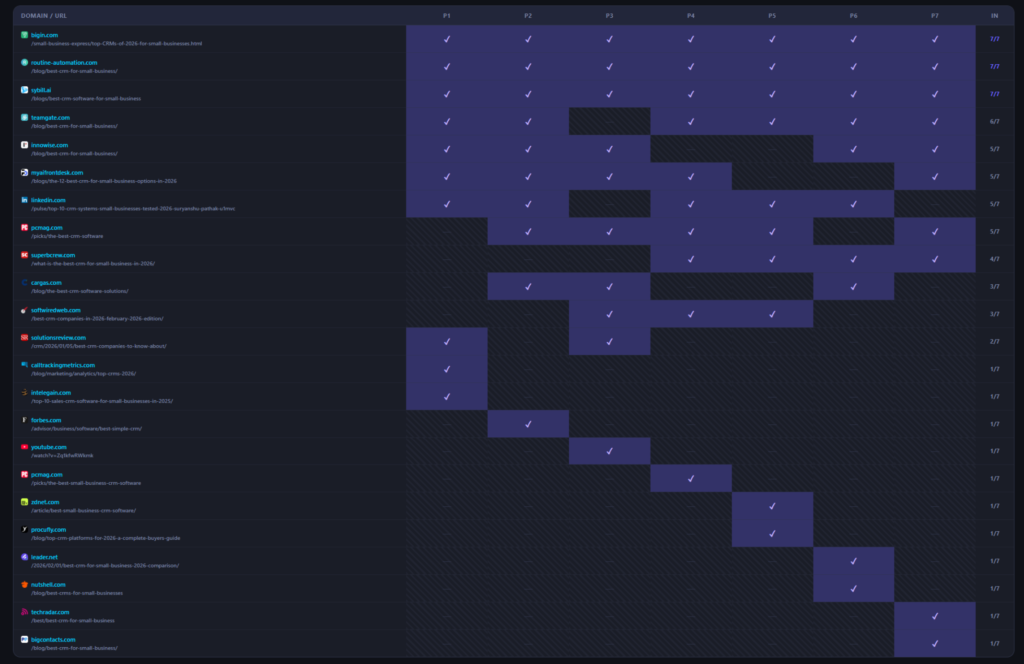
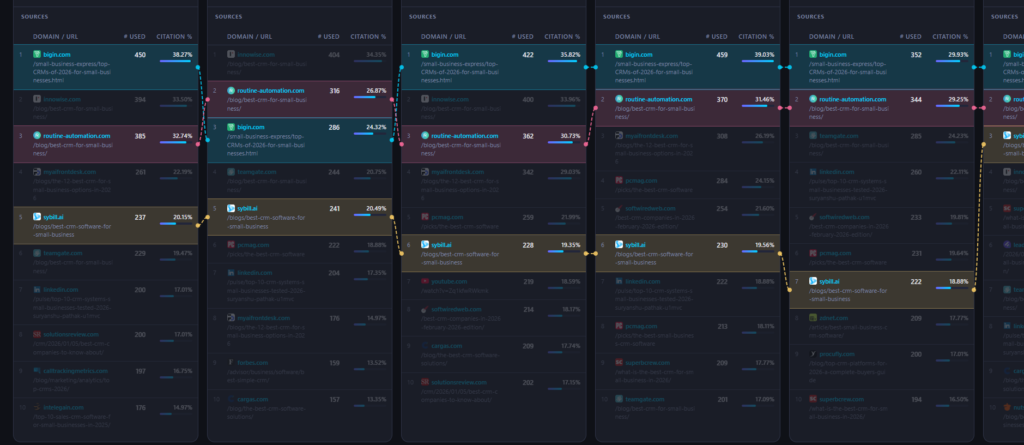
8. Source Variation Across Prompts
Research question: Do different prompt phrasings trigger different sources?
Source selection is significantly more sensitive to phrasing than brand rankings. Across the seven prompts, 22 unique domains were surfaced in the top-10 sources, despite the prompts being semantically near-identical.
| Frequency | Domains | Interpretation |
| 7/7 — Universal | bigin.com, routine-automation.com, sybill.ai | Structural anchors — always cited |
| 6/7 | teamgate.com, pcmag.com | Near-universal — very high consistency |
| 5/7 | linkedin.com, innowise.com, myaifrontdesk.com | High consistency — reliable sources |
| 3–4/7 | softwiredweb.com, superbcrew.com, cargas.com | Conditional — appear with certain phrasings |
| 1/7 — Prompt-specific | calltrackingmetrics.com, intelegain.com, forbes.com, youtube.com, leader.net, zdnet.com, procufly.com, nutshell.com, techradar.com, bigcontacts.com | Only activated by specific wording |
10 out of 22 domains (45%) appear in exactly one prompt (top 10). This demonstrates that the AI’s source retrieval behaviour is substantially driven by specific lexical cues in the query. While the brand ranking output is stable, the evidential layer beneath it shifts considerably with each variation.
9. Universally Cited Sources
Research question: Which sources are consistently cited across all variations?
Three domains appeared in the top-10 sources of every single prompt tested:
- bigin.com — /small-business-express/top-CRMs-of-2026-for-small-businesses.html
The most frequently cited page in the dataset, with citation counts ranging from 202 to 539 across prompts. This page appears to be treated by the AI as a high-authority, comprehensive reference for the CRM-for-SMB topic cluster. - routine-automation.com — /blog/best-crm-for-small-business/
Consistently in the top 3 most-cited sources. Cited 316–370 times across the relevant prompts. - sybill.ai — /blogs/best-crm-software-for-small-business
Present across all 7 prompts, cited 187–331 times. Notable as an AI-native company whose blog content is being cited as a reference source for CRM recommendations.
Strategic implication: These three pages represent the AI’s foundational reference layer for this topic. Any brand aiming to maximise AI visibility for CRM-related queries should study what these pages say about them, how they rank them, and what language they use, as this content directly shapes AI-generated answers regardless of how a user phrases their query.
10. Prompt-Specific Sources
Research question: Are there sources that only appear when specific wording is used?
Ten domains appear in the top 10 for exactly one prompt, suggesting they are more activated by specific lexical triggers rather than broad topic relevance:
| Domain | Appears only in | Likely lexical trigger |
| calltrackingmetrics.com | P1 | “top” — may index differently in analytics/performance content |
| intelegain.com | P1 | “top” — similar pattern to above |
| forbes.com | P2 | “best … tools” — editorial authority content |
| youtube.com | P3 | “leading” — video content uses this qualifier more |
| zdnet.com | P5 | “solutions” — enterprise tech vocabulary |
| procufly.com | P5 | “solutions” — procurement-adjacent terminology |
| leader.net | P6 | “software tools” — software review ecosystem |
| nutshell.com | P6 | “software tools” — competitor content in software framing |
| techradar.com | P7 | “mid-sized” — tech media uses this term specifically |
| bigcontacts.com | P7 | “mid-sized” — different content corpus than “medium-sized” |
The “mid-sized” vs. “medium-sized” distinction (P7 vs. P1–P6) is particularly revealing. Despite being semantically equivalent, the two phrasings pull from different training data corpora. Tech media outlets (techradar.com) and certain CRM vendors (bigcontacts.com) preferentially use “mid-sized” in their content, causing them to surface only when that exact term is used in the prompt. This confirms that the AI is not performing semantic equivalence mapping, it is pattern-matching on vocabulary.
Techradar used 1x mid-sized in the text, 0x medium-sized.
Bigcontacts used 1x midsize in the text, 0x medium-sized.

11. Prompt Intent Clustering
Research question: Can these prompts be clustered into the same “AI intent group,” or do they behave as separate queries?
All seven prompts operate within a single primary intent cluster: they share the same topic (CRM), audience (SMBs), time frame (2026), and output format (ranked list).
Sub-group A — “best/top + tools” (P1, P2, P6, P7)
These four prompts produce the most consistent results. Source sets overlap significantly, and visibility scores for the mid-tier are relatively stable. P7 is a partial outlier due to the “mid-sized” term activating a different content corpus, particularly for sources, while brand rankings remain aligned.
Sub-group B — “leading” / “platforms” / “solutions” (P3, P4, P5)
These prompts produce elevated visibility scores for Monday, Salesforce, and Freshworks, and surface more varied source sets. P3 (“leading”) is the most distinct prompt in the dataset, it uniquely activates youtube.com and softwiredweb.com, produces the highest Monday score (78%), and elevates Freshworks to its maximum (37%). The word “leading” appears to activate a different register of training content (editorial rankings, analyst reports, and industry commentary) compared to the more consumer-facing “best” framing.
Conclusion on clustering: These are one intent group with measurable internal heterogeneity. They should be treated as a single “topic cluster” for brand tracking purposes, but monitored collectively rather than through any single representative prompt. Using P2 (“best CRM tools”) alone as a proxy for the full cluster would systematically underestimate Monday’s AI presence by up to 19 percentage points.
12. Overall Conclusion & Strategic Implications
Research question: To what extent do minor prompt variations influence brand visibility and source selection in AI-generated answers for CRM tools?
On brand visibility scores
Minor prompt variations have a moderate to significant impact on visibility percentages, particularly for brands in positions 4–9. A 19-point swing for Monday and a 13-point swing for Salesforce across near-identical prompts demonstrates that the AI is not retrieving a static score, it is dynamically weighting brands based on word associations in its training data.
On source selection
Minor prompt variations have a significant impact on source selection. Only 14% of discovered domains (3 of 22) appear in every prompt. The remaining 86% are sensitive to phrasing, with 45% appearing in only one of the seven prompts tested. This has direct implications for content strategy: the AI draws on different pools of content depending on exact vocabulary, even when the informational intent is identical.
Strategic recommendations
- Track multiple prompt variants. A single prompt measurement gives an incomplete picture. For reliable AI visibility benchmarking, use a minimum of 3–4 prompt variants per topic cluster and report on the range as well as the average.
- Prioritise the universal sources. bigin.com, routine-automation.com, and sybill.ai are the AI’s foundational references for this topic. Securing favourable mentions on these pages — or producing content that competes with them — offers the highest leverage for improving AI visibility across all prompt variants.
- Optimise content vocabulary for your tier. If your brand is in the mid-tier (rank 4–9), the word choices in your content can shift your AI representation by 10–19 percentage points. Publishing content that uses the vocabulary associated with your highest-performing prompt variant (“leading”, “mid-sized”, “platforms”) may incrementally improve your AI visibility score.
